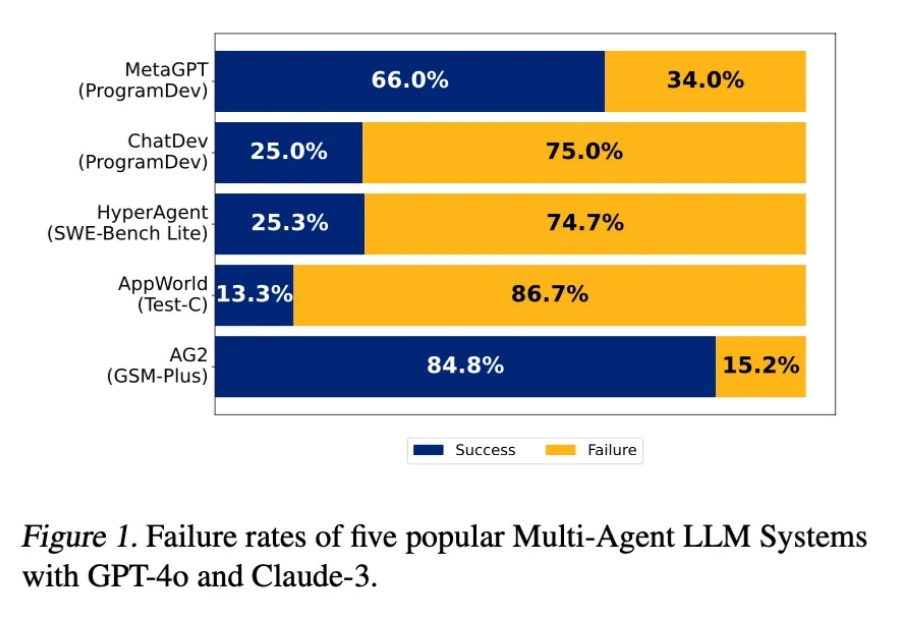
Multi-Agents 系统太难搞了,不要轻易尝试 | UC Berkeley 论文分享
Multi-Agents 系统太难搞了,不要轻易尝试 | UC Berkeley 论文分享这两年,AI 领域最激动人心的进展莫过于大型语言模型(LLM)的崛起,LLM 展现了惊人的理解和生成能力。
来自主题: AI技术研报
10780 点击 2025-03-28 09:33
 搜索
搜索
这两年,AI 领域最激动人心的进展莫过于大型语言模型(LLM)的崛起,LLM 展现了惊人的理解和生成能力。
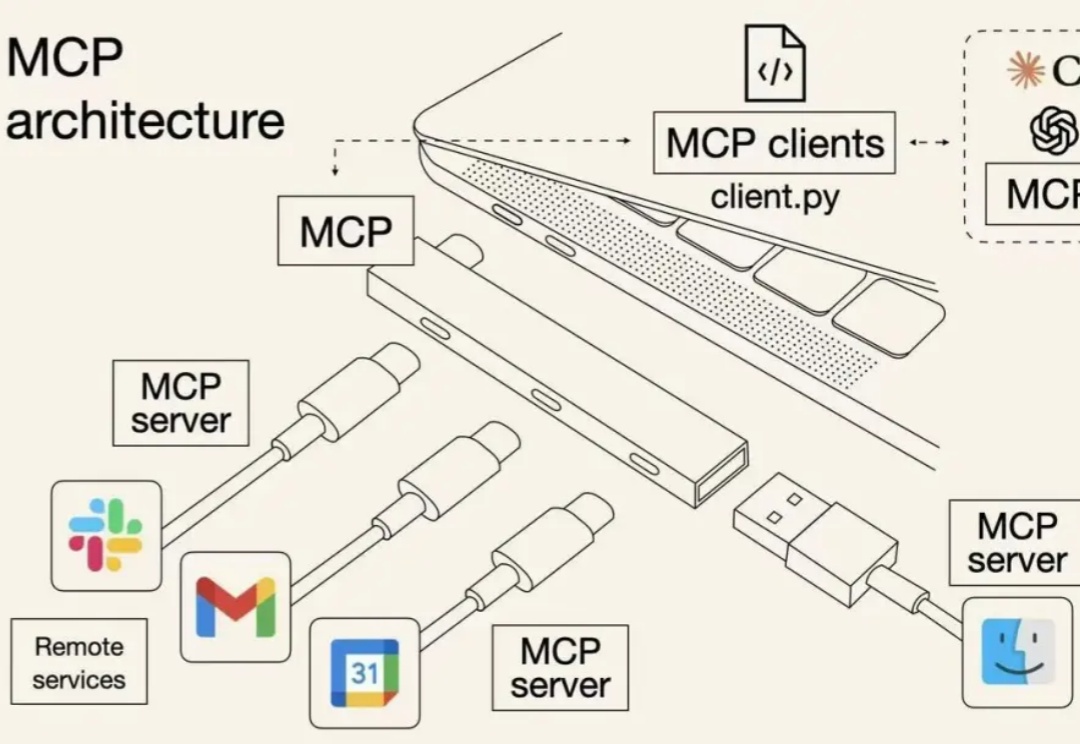
在拾象团队的 2025 的 AI 关键预测中,我们提到:随着 Agent 时代到来,OS 才是 LLM 厂商们最高的护城河,从 computer use 到 MCP,Anthropic 构建 OS 的决心是 AI labs 中最强、最明显的。

清华智能产业研究院(AIR)博三在读,去年六月份,出于对语言模型 LLM 的强烈兴趣,加入了字节 as Top Seed Intern,在人工智能的最前沿进行探索。刚好这个话题和我现在做的工作强相关,我分享一下自己的观点和亲身体验。

如果你让当今的 LLM 给你生成一个创意时钟设计,使用提示词「a creative time display」,它可能会给出这样的结果:
近年来,大型语言模型(LLM)通过大量计算资源在推理阶段取得了解决复杂问题的突破。推理速度已成为 LLM 架构的关键属性,市场对高效快速的 LLM 需求不断增长。
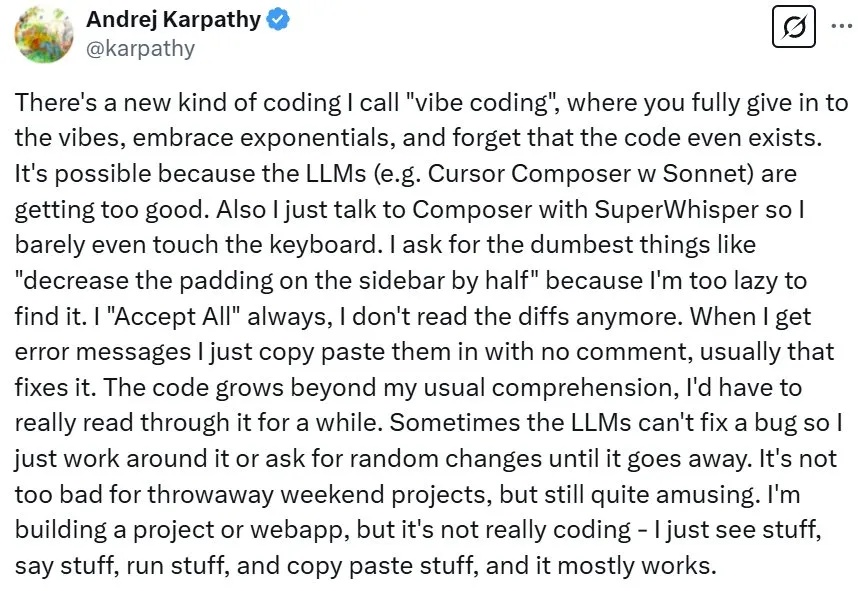
近段时间,著名 AI 科学家 Andrej Karpathy 提出的氛围编程(vibe coding)是 AI 领域的一大热门话题。简单来说,氛围编程就是鼓励开发者忘掉代码,进入开发的氛围之中。更简单地讲,就是向 LLM 提出需求,然后「全部接受」即可。

DeepSeek 提出的 GRPO 可以极大提升 LLM 的强化学习效率,不过其论文中似乎还缺少一些关键细节,让人难以复现出大规模和工业级的强化学习系统。
HuixiangDou 是群聊场景的 LLM 知识助手。

Neurobo(弈智交互)是一家位于上海的创业公司,获得前百度总裁、微软副总裁陆奇博士创办的奇绩创坛的投资。团队核心成员来自清华大学与日本筑波大学等海内外名校,致力于结合 LLM 与现实场景数据,让二次元用户可以将「谷子」变为随身相伴,随时触达的实体情感伴侣。

LLM 在生成 long CoT 方面展现出惊人的能力,例如 o1 已能生成长度高达 100K tokens 的序列。然而,这也给 KV cache 的存储带来了严峻挑战。